I want to share my thoughts on LLM leaderboards. The thing is, accurately testing and evaluating models is quite difficult. Performance can vary depending on the type of task and context.
I believe that there is no point in delving too deeply into a detailed comparison of the positions of models in the leaderboards. Instead, it is better to divide them into several groups: leaders, middle, and laggards. This will give a more realistic idea of their capabilities and help avoid over-fixation on minor differences in scores.
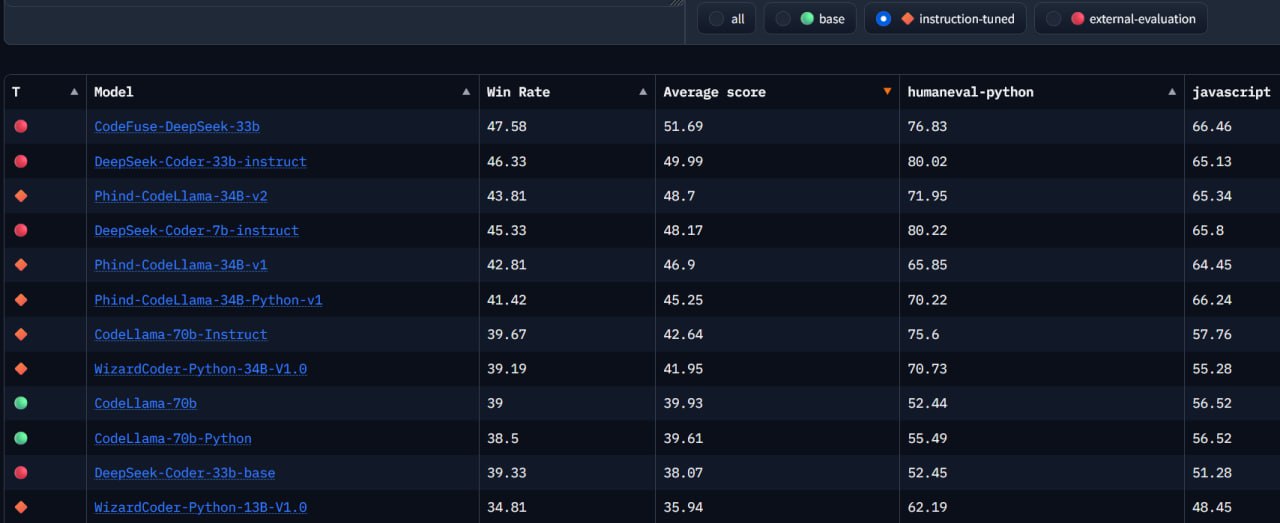
🤗 On the bigcode-models-leaderboardthere are only open models, on the screen I filtered instruct with which you can interact as in a chat, giving instructions.
In general, DeepSeek and Phind-CodeLlama of sizes 33B and 34B showed the best performance. The table does not yet have Phind-CodeLlama 70B and it is not yet known whether the developers will make it open source